

Streamlit Blog
Customize Llamas personality by clicking the settings button I can explain concepts write poems and code solve logic puzzles or even name your pets Send me a message or upload an image or audio file. This Space demonstrates model Llama-2-7b-chat by Meta a Llama 2 model with 7B parameters fine-tuned for chat instructions Feel free to play with it or duplicate to run generations without a queue. Ask any question to two anonymous models eg ChatGPT Claude Llama and vote for the better one You can continue chatting until you identify a winner Vote wont be counted if model identity is revealed during. Llama 2 is pretrained using publicly available online data An initial version of Llama Chat is then created through the use of supervised fine-tuning Next Llama Chat is iteratively refined using. Across a wide range of helpfulness and safety benchmarks the Llama 2-Chat models perform better than most open models and achieve comparable performance to ChatGPT according to human..
. . Llama 2 encompasses a range of generative text models both pretrained and fine-tuned with sizes from 7 billion to 70 billion parameters. Could not load Llama model from path Xxxxllama-2-7b-chatggmlv3q4_0bin Issue 438 PromtEngineerlocalGPT GitHub. Llama 2 is released by Meta Platforms Inc This model is trained on 2 trillion tokens and by default supports a context length of 4096..
Instruction-tune Llama 2 a guide to training Llama 2 to generate instructions from inputs transforming. Web Training LLMs can be technically and computationally challenging In this section we look at the tools available. Web Select the Llama 2 model appropriate for your application from the model catalog and deploy the model using the PayGo. . Web Llama 2 family of models Token counts refer to pretraining data only All models are trained with a. We are unlocking the power of large language models. Web Llama 2 models are text generation models You can use either the Hugging Face LLM inference. Web Llama2 pad token for batched inference - Models - Hugging Face Forums..
Result To run LLaMA-7B effectively it is recommended to have a GPU with a minimum of 6GB VRAM A suitable GPU example for this model is the. Result For 7B Parameter Models If the 7B Llama-2-13B-German-Assistant-v4-GPTQ model is what youre after you gotta think about hardware in. Result Some differences between the two models include Llama 1 released 7 13 33 and 65 billion parameters while Llama 2 has7 13 and 70 billion parameters. Result Hence for a 7B model you would need 8 bytes per parameter 7 billion parameters 56 GB of GPU memory If you use AdaFactor then you need 4. ..
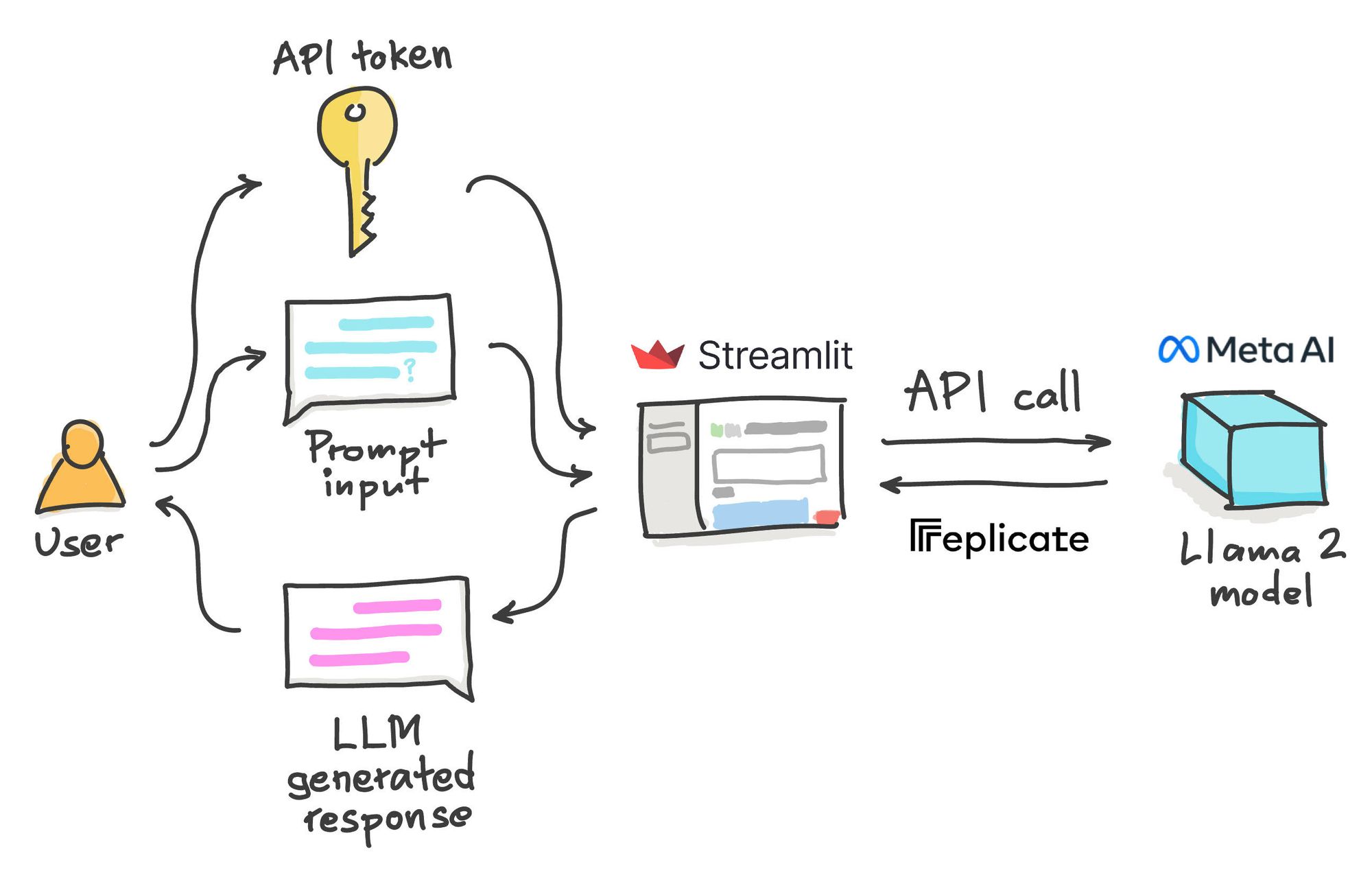
Streamlit Blog





Komentar